mdTranslator
mdTranslator Architecture Overview
The mdTranslator's work flow is logically divided into the following processes:

After invoking the mdTranslator via one of the methods described in Usage, the mdTranslator examines the passed in parameters and turns control over to the requested reader.
The reader manages the next two processes (Validate and Read). If the reader processes comes to successful completion, mdTranslator will call the requested writer.
The writer then manages the process of translating the metadata content into the requested format. The writer then hands the result back to mdTranslator to handle output of the package in the format requested by the user. Each of these primary processes are described in more detail on the following pages.
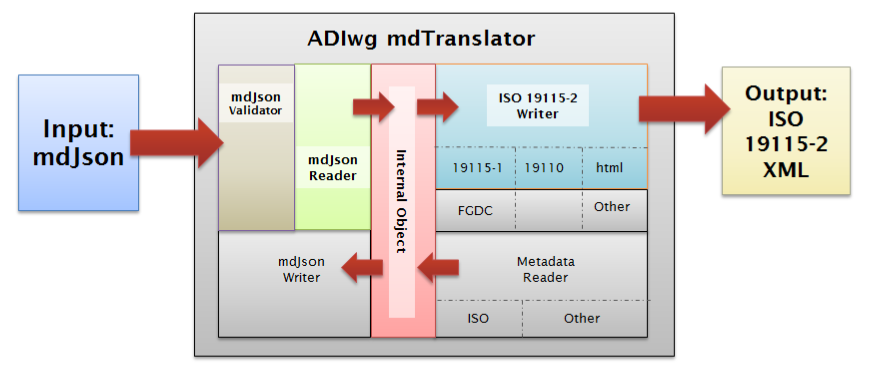
The mdTranslator architecture has been designed to support multiple readers and writers all of which use mdTranslator's internal object to store and retrieve metadata content. In this way content from any reader can be translated into output via any of the mdTranslator's writers.
In the depiction of the mdTranslator architecture below a metadata input file formatted in mdJson is passed through mdTranslator to generate ISO 19115_2 XML metadata.